
Question: You are given the head pointer to 2 single Linked Lists, and both of the lists converge at a certain point and then advance forward. We need to find the address of the node, at which both of the Linked Lists meet.
Input:
4 -> 8 -> 15 ->
42 -> 99
16 -> 23 ->Output: 42
Suppose there are two single Linked Lists both of which intersect at some point and become a single Linked list. The head or start pointer of both the lists are known, but the intersecting node is not known. Also, the number of nodes in each of the list before they intersect are unknown and both lists may have a different length. The total length of the lists is also unknown, means we are just provided with the head pointers and nothing else. We have to find the intersection point.
Let us take a look at the visualization of the actual problem.
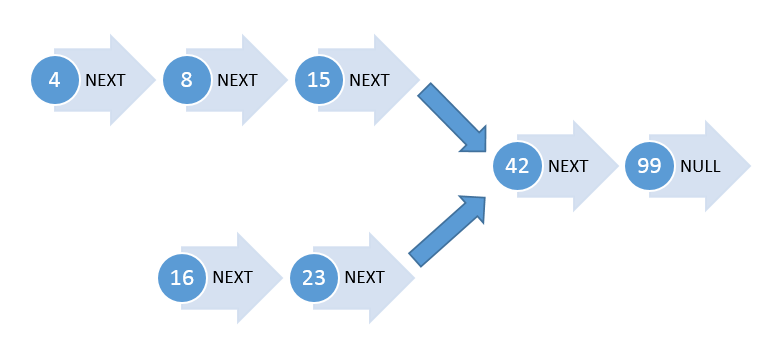 In this case, 42 is the merging point of both the lists and hence our answer. Let us see, how we can approach the problem.
In this case, 42 is the merging point of both the lists and hence our answer. Let us see, how we can approach the problem.
METHOD 1: BRUTE – FORCE APPROACH
This is the easiest method, and in this method we compare each node of List 1 with each node of List 2. If the address of both is same, we return the node.
struct node * yNodeBruteForce(struct node *head1, struct node * head2)
{
// stores the result, if no node is intersecting we return NULL
struct node * temp = NULL;
struct node * temp2;
while(head1 != NULL)
{
temp2 = head2;
while(temp2 != NULL)
{
if(head1 == temp2)
{
// found a matching node
temp = head1;
break;
}
else
temp2 = temp2 -> next;
}
}
return temp;
}
The problem here is that the time complexity is very high. If list1 is of length ‘m’ and list2 of length ‘n’, then
Time Complexity:- O(m*n)
Space Complexity:- O(1)
METHOD 2: USING A HASH TABLE
This method is similar to the brute force method. The following steps are involved in it:-
- Select a List, that has fewer number of elements. We can get the number of elements, by a single scan on both the lists. If both the lists have same number of elements, select any list at random.
- Create a hash table using the list with fewer elements. Creating a hash table means storing the address of each of the nodes of the smaller list in a separate data structure such as an array.
- Now, traverse the other list and compare the address of each of the node with the values in the hash table.
- If there exists an intersection point, certainly we will find a match in the hash table and we will obtain the intersection point.
Time Complexity: Time for creating hash table + Time for scanning the list
Space Complexity: O(m) or O(n), depending upon the smaller size list.
METHOD 3: USING STACKS
We can solve this problem using the concept of stacks. A stack is a data structure which follows the principle of LAST IN FIRST OUT (LIFO). The steps involved in solving the problem using stacks are:-
- Create 2 different stacks for both the lists.
- Push all the elements of both the lists in the 2 stacks.
- Now start POPing the elements from both the stacks at once.
- Till both the lists are merged, we will get the same value from both the stacks.
- As soon as both the stacks return different value, we know that the last popped element was the merging point of the lists.
- Return the last popped element from the stack.
struct node
{
int data;
struct node * data_node;
struct node * next;
};
// defining a function to push all the nodes of the list
// this is NOT a generic PUSH function for stacks
struct node * pushAllNodes(struct node * head)
{
//creating first node
if(head)
{
struct node * temp = (struct node *)malloc(sizeof(struct node));
temp -> data_node = head;
temp -> next = NULL;
}
head = head -> next;
// creating rest of the stack
while(head)
{
struct node * temp2 = (struct node *)malloc(sizeof(struct node));
temp2 -> data_node = head;
temp2 -> next = temp1;
temp1 = temp2;
head = head -> next;
}
return temp2;
}
//implementing a function to find the intersection point using stacks
struct node * yNodeStacks(struct node * head1, struct node * head2)
{
//creating 2 stacks
struct node * stack1;
struct node * stack2;
//pushing all the nodes of the 2 lists in 2 stacks
stack1 = pushAllNodes(head1);
stack2 = pushAllNodes(head2);
//to find the previous node
struct node * prev = stack1;
//keep POPing elements till the address is same
while(stack1 -> data_node == stack2 -> data_node)
{
prev = stack1;
stack1 = stack1 -> next;
stack2 = stack2 -> next;
}
return prev;
}
Time Complexity: O(m+n) for scanning both the lists.
Space Complexity: O(m+n) for creating the two stacks.
METHOD 4: USING A SORTING AND SEARCHING TECHNIQUE
We can combine two techniques to get a solution to the problem. This can be done as:-
- Create an array and store all the addresses of the nodes.
- Now sort this array.
- For each element in the second list, from the beginning search for the address in the array. We can use a very efficient search algorithm like Binary Search which gives us the result in O(log n).
- If we find a same memory address, that means that is the merging point of the 2 lists.
Time Complexity: Time for sorting + Time for searching each element = O(Max(m*log(m), n*log(n)))
Space Complexity: O(Max(m,n))
METHOD 5: FURTHER IMPROVING THE COMPLEXITY ( THE BEST APPROACH )
This approach is the most efficient approach and utilizes a little brain power and a little maths trick, which can really give us a fast solution to the problem. The steps involved are:-
- Find the length of both the lists. Let ‘m’ be the length of List 1 and ‘n’ be the length of List 2.
- Find the difference in length of both the lists. d = m – n
- Move ahead ‘d’ steps in the longer list.
- This means that we have reached a point after which, both of the lists have same number of nodes till the end.
- Now move ahead in both the lists in parallel, till the ‘NEXT’ of both the lists is not the same.
- The NEXT at which both the lists are same is the merging point of both the lists.
#include <stdio.h>
#include <stdlib.h>
struct node
{
int data;
struct node * next;
};
// helper function to get the count of both the lists.
int getCount(struct node * head)
{
int count = 0;
while(head)
{
head = head -> next;
count++;
}
return count;
}
struct node * yNodeIntersecting(struct node * head1, struct node * head2)
{
// get count of both the lists
int m = getCount(head1);
int n = getCount(head2);
//to store the merge point
struct node * merge_point = NULL;
// finding the value of d based on the longer list
int diff = (m > n) ? (m-n) : (n-m);
//traverse the smaller longer list for 'diff' steps
if(m > n)
{
while(diff--)
head1 = head1 -> next;
}
else
{
while(diff--)
head2 = head2 -> next;
}
// now both lists have equal nodes till the end.
while(head1 && head2)
{
if(head1 -> next == head2 -> next)
{
merge_point = head1 -> next;
break;
}
head1 = head1 -> next;
head2 = head2 -> next;
}
return merge_point;
}
struct node * addElement(struct node *head, int number)
{
struct node * temp = (struct node*)malloc(sizeof(struct node));
temp -> data = number;
temp -> next = NULL;
struct node * temp2 = head;
while(temp2 -> next != NULL)
temp2 = temp2 -> next;
temp2 -> next = temp;
return head;
}
int main(void)
{
//creating a list
struct node * listHead1 = (struct node*)malloc(sizeof(struct node));
listHead1 ->data = 4;
listHead1 ->next = NULL;
listHead1 = addElement(listHead1, 8);
listHead1 = addElement(listHead1, 15);
listHead1 = addElement(listHead1, 42);
listHead1 = addElement(listHead1, 99);
struct node * listHead2 = (struct node*)malloc(sizeof(struct node));
listHead2->data = 16;
listHead2->next = NULL;
listHead2 = addElement(listHead2, 23);
struct node * temp = listHead2;
temp = temp-> next;
temp -> next = listHead1 -> next -> next -> next;
struct node * merge_p = yNodeIntersecting(listHead1, listHead2);
printf("Merge node is:- %d", merge_p -> data);
return 0;
}
Time Complexity: O(max(m,n))
Space Complexity: O(1)
1 comment
Very nicely you’ve explained it. Thanks
Comments are closed.