
Question: Given an array of strings
strs, you need to group all the anagrams together. You can return the answer in any order.Input:
strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
Output:[["bat"], ["nat", "tan"], ["ate", "eat", "tea"]]
Let us try to understand the problem statement and its test cases first.
You are provided with an array that has some strings. You need to group all the anagrams together. It could be possible that some strings don’t find anagrams, and that is perfectly fine. It can exist as an individual group. Return this group in any order.
Let us look at a sample test case:

You must also understand, what is an Anagram? Two strings are said to be anagrams of each other if they are made up of the same characters with same frequency. For example: the word LISTEN and SILENT are anagrams. They are composed of the letters E, I, L, N, S, T.
With this definition in mind, in the below image you can see all the highlighted anagrams. So, tan and nat are said to be anagrams and they form a group. Just like this, we need to group all the anagrams together, and form a resultant output.
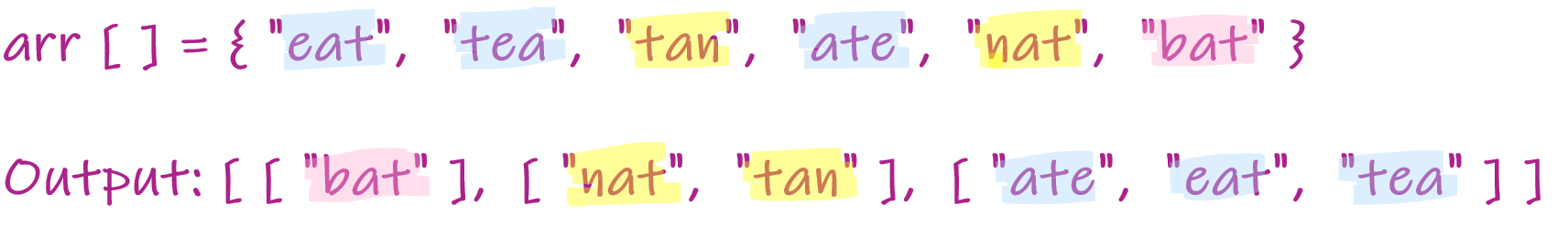
A brute force method to solve this problem would be very obvious.
- Iterate over each string in the input array.
- For each string, check with each element of the array if they are anagrams.
- If it is an anagram, add it to a group.
- Else, move the string to a different group.
This method would work but you will run out of time trying to execute it for large test cases.
Method 1: Group by Sorting
One way to solve this problem is to group via sorting. Think about the properties of anagrams. If two words are anagrams of each other, they contain exactly the same characters. So, if we sort both of them, we should theoretically get the exact same string.
Let us look at a sample input.

Now, as a next step, try to sort all of them and look at the sorted strings. You will find some strings that look exactly alike. That is because they were anagrams. You can now just compare these sorted strings.
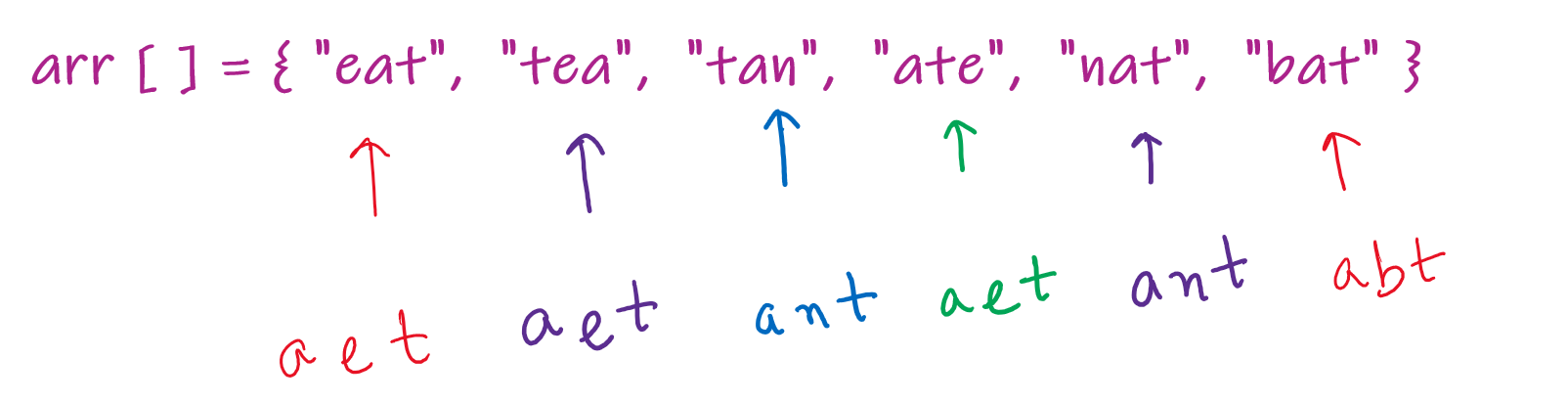
Once you have the sorted strings, you can create a hashmap, that will store all the groups. The key will be the sorted string, and the value would be the list of all the strings that are anagrams.
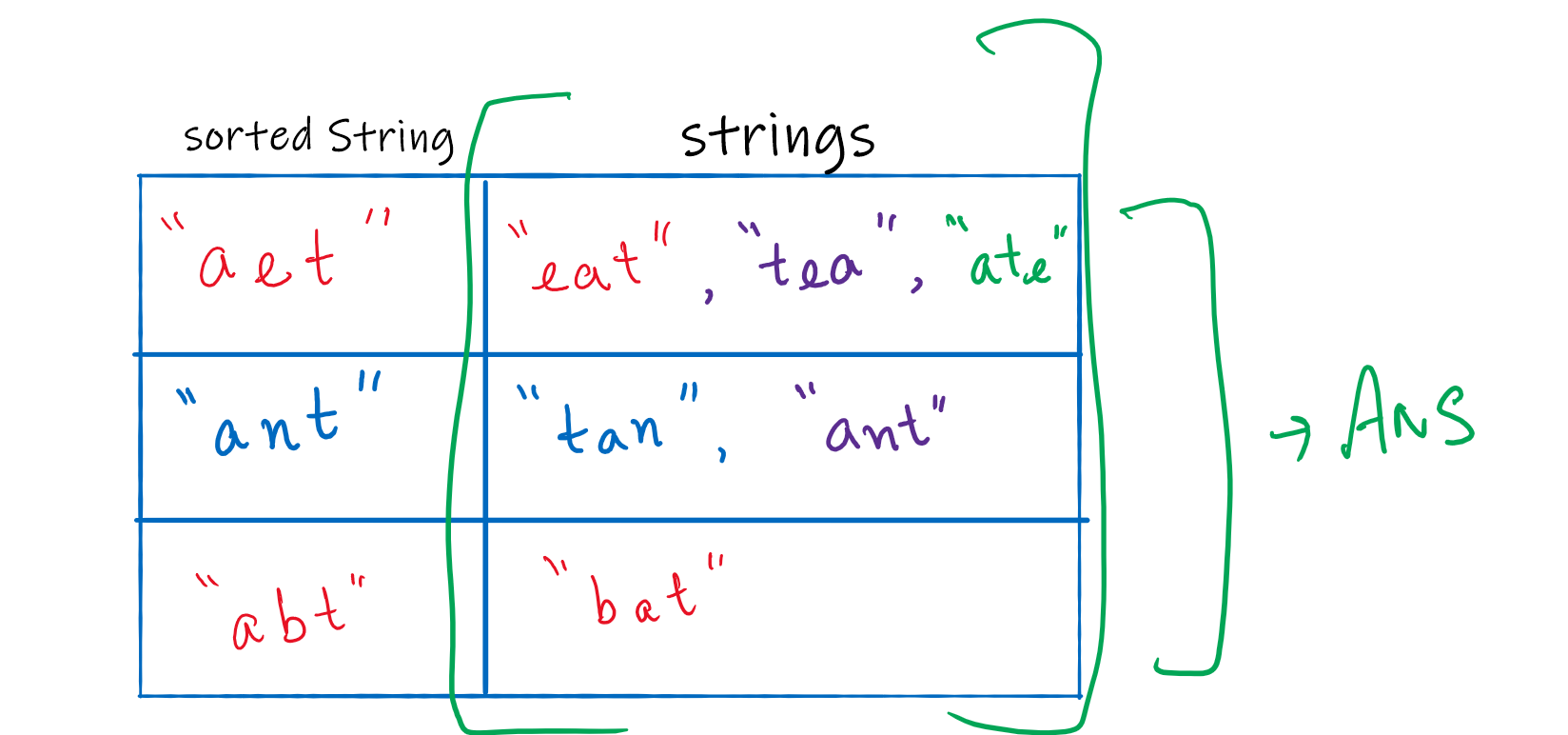
After you iterate over all the strings, the values in the hashmap will give you the required groups. The time complexity of this approach depends on the sorting technique you use to sort the strings.
Implementation:
public List<List<String>> groupAnagramsCategorizeBySorting(String[] strs) {
if (strs == null || strs.length == 0)
return new ArrayList<>();
Map<String, List<String>> stringAnagramsMap = new HashMap<>();
for (String s : strs) {
char[] arr = s.toCharArray();
Arrays.sort(arr);
String key = String.valueOf(arr);
if (!stringAnagramsMap.containsKey(key))
stringAnagramsMap.put(key, new ArrayList<>());
stringAnagramsMap.get(key).add(s);
}
List<List<String>> resultList = new ArrayList<>();
for (Map.Entry<String, List<String>> stringAnagrams : stringAnagramsMap.entrySet()) {
resultList.add(stringAnagrams.getValue());
}
return resultList;
}
Code language: Java (java)Time Complexity: O(n * \log k) (k is the length of largest string)
Space Complexity: O(n)
Method 2: Group by Frequency
It is however possible to improve the above approach a little bit. We can also take advantage of the fact that two anagrams have the same frequency of characters as well. So, instead of sorting the strings, we can also generate a new string to exhibit this property.
Example: The word KNEE and KEEN are anagrams. You can also say that both these words have K - 1 times, E - 2 times and N - 1 time. Using this method we can create some kind of a frequency string which can be something like E2K1N1. Notice that this string would be same for both the words.
Let us take up an example once again.

We can now create frequency strings for each of these strings. They will look like:
aab = a2b1
aba = a2b1
baa = a2b1
abbccc = a1b2c3
abb = a1b2
bcbcca = a1b2c3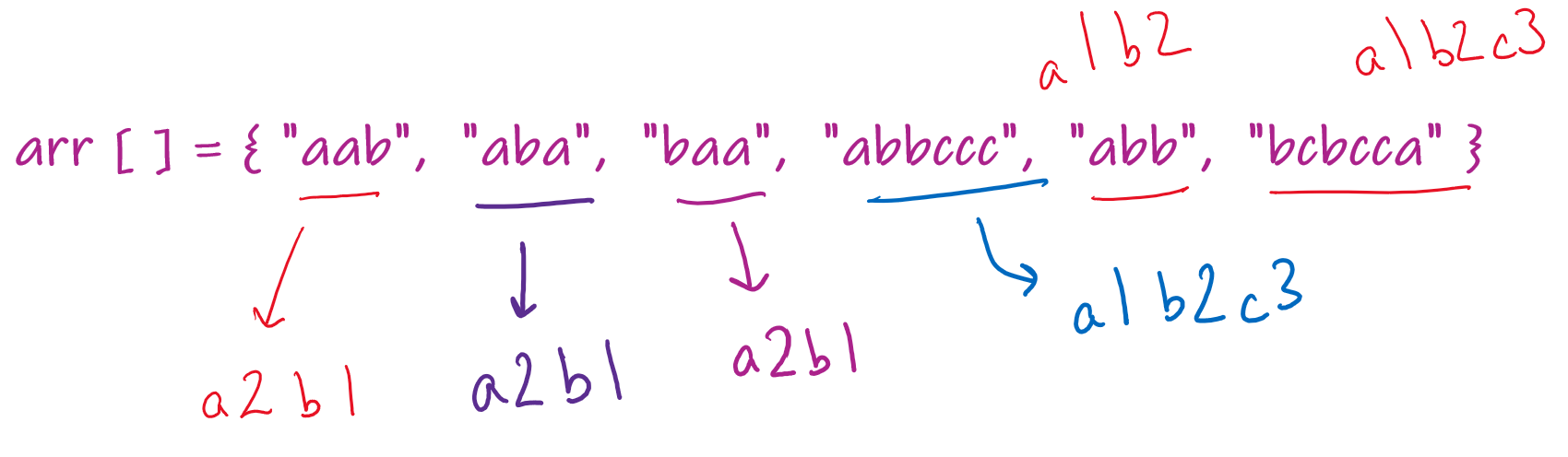
Looking closely at the frequency strings, you can conclude that all anagrams will generate the same frequency strings. This gives you some key to group all the anagrams. Once again, you can create a hashmap that will have the key as the frequency string, and the value would be a list of all the anagrams
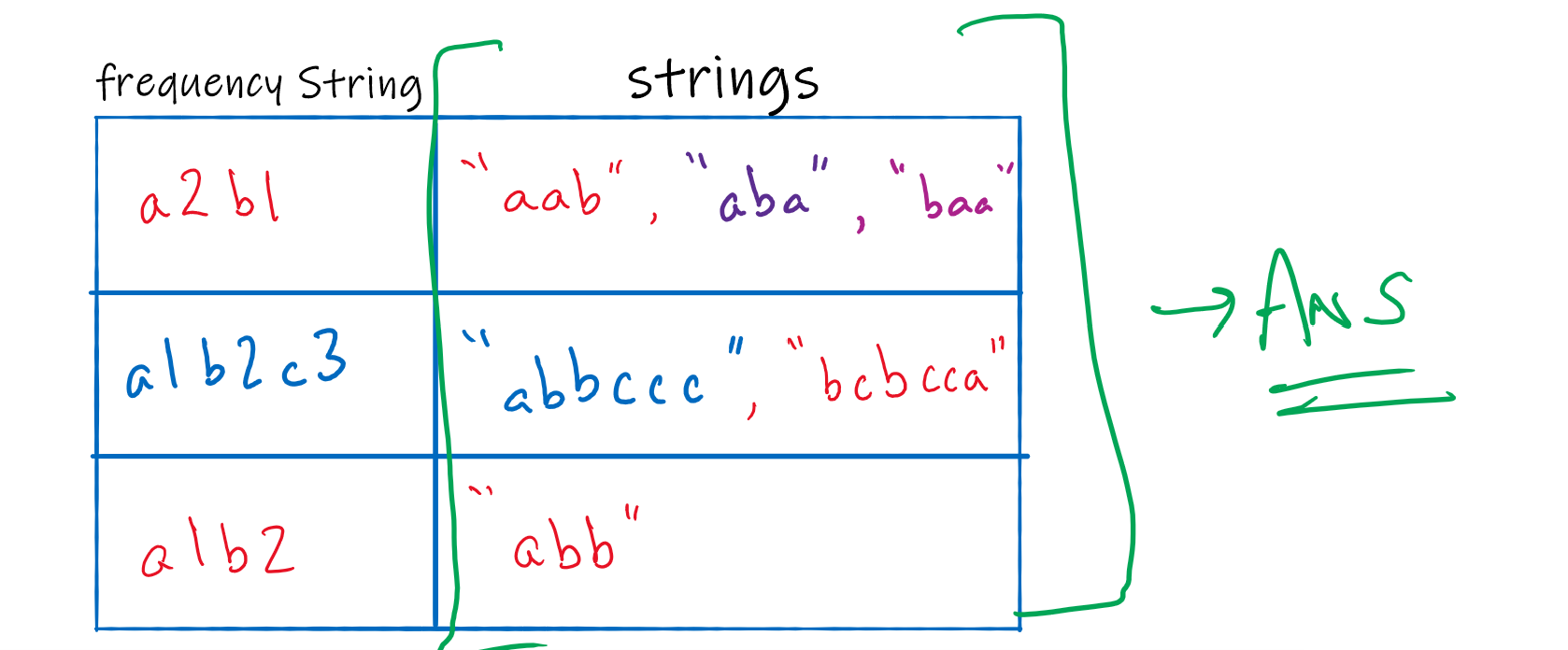
After you iterate over all the strings, you should have all your groups in the values of the hashmap. The time complexity of this approach can be better as frequency strings can be generated in linear time.
Implementation:
public List<List<String>> groupAnagramsCategorizeByFrequency(String[] strs) {
// Check for empty inputs
if (strs == null || strs.length == 0)
return new ArrayList<>();
Map<String, List<String>> frequencyStringsMap = new HashMap<>();
for (String str : strs) {
String frequencyString = getFrequencyString(str);
// If the frequency string is present, add the string to the list
if (frequencyStringsMap.containsKey(frequencyString)) {
frequencyStringsMap.get(frequencyString).add(str);
}
else {
// else create a new list
List<String> strList = new ArrayList<>();
strList.add(str);
frequencyStringsMap.put(frequencyString, strList);
}
}
return new ArrayList<>(frequencyStringsMap.values());
}
private String getFrequencyString(String str) {
// Frequency buckets
int[] freq = new int[26];
// Iterate over each character
for (char c : str.toCharArray()) {
freq[c - 'a']++;
}
// Start creating the frequency string
StringBuilder frequencyString = new StringBuilder("");
char c = 'a';
for (int i : freq) {
frequencyString.append(c);
frequencyString.append(i);
c++;
}
return frequencyString.toString();
}
Code language: Java (java)Time Complexity: O(n * k) (k is the length of the largest string)
Space Complexity: O(n)
As always, the complete code and its test cases can be found on Github as well.
Video Explanation:

1 comment
Hi Geeks
You can checkout an easy explanation for the problem in the below video :)
https://www.youtube.com/watch?v=n3ErPv4wL88
Comments are closed.